The AXI DMA core is a soft Xilinx IP core to be used with the Xilinx Vivado® Design Suite. The AXI DMA provides high-bandwidth direct reminiscence entry between reminiscence and AXI4-Stream target peripherals. Its elective scatter/gather capabilities additionally offload knowledge movement tasks from the Central Processing Unit (CPU). Maybe every mixture is answerable for 1 byte of information (i am simply assuming). Might be the software driver for max btt is 8MB for contiguous memory, but don’t clarify about 2KB at 14bit buffer size register.
Earlier Than writing any code, let’s review how the only kind of STM32 DMA peripheral works in theory. A lot of this might be review if you’re already familiar with https://www.xcritical.com/ DMA and/or STM32 peripherals, so…sorry if it’s boring. Ddi_dma_mem_free(9F) is used to free the reminiscence allocated by ddi_dma_mem_alloc(9F).
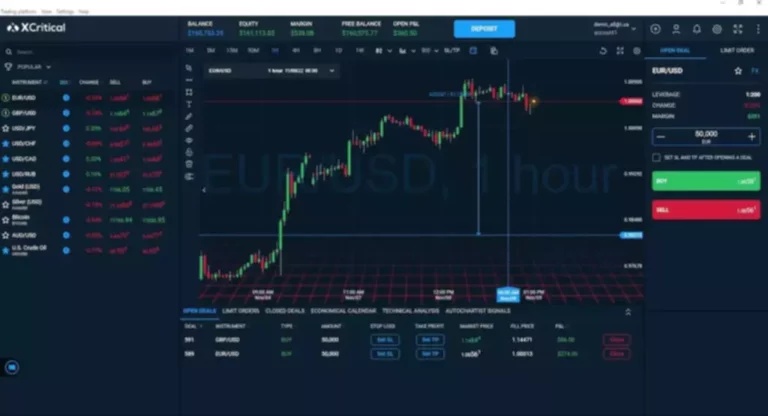
Pynq Dma Tutorial (part 1: Hardware Design)
If there is no scatter-gather capability, then the size of each DMA switch might be a multiple of this value. You do not have to ensure the DMA object is locked in memory in block drivers for buffers coming from the file system, because the file system has already locked the info in memory. This example demonstrates tips on how to switch packets in interrupt mode when the core is configured in easy direct market access DMA mode. If you wish to switch a stream of 136 bits, once more you have to determine the way you retailer these in memory, transfer 32/64 bits at a time and deserialise into your 136 bit type. You might probably retailer 136 bits contiguously (i.e. not byte aligned) and increase the effectivity of the reminiscence transfer, but the logic to unpack your 136 bits will be more sophisticated. You can increase the burst width to enhance efficiency of your knowledge transfers.
Dma Background
- The DMA AXI master ports have to be linked to the PS DRAM.
- So what we referred to as ‘channels’ in the previous instance are actually known as ‘streams’, and ‘channel’ means one thing else.
- You don’t have to make sure the DMA object is locked in reminiscence in block drivers for buffers coming from the file system, as the file system has already locked the data in reminiscence.
- If the CPU accesses the reminiscence, it would learn the incorrect data from the CPU cache.
This handle is opaque to the device driver; the motive force should save the handle and move it in subsequent calls to DMA routines, however should notinterpret it in any way. Drivers specify the DMA burst sizes that their gadget supports http://sabda.rplgtbi.web.id/?p=39830 within the dma_attr_burstsizes field of the ddi_dma_attr(9S)structure. Nonetheless, when DMA resources are allocated, the system would possibly impose further restrictions on the burst sizes that might be really used by the device. The ddi_dma_burstsizes(9F) routine can be utilized to obtain the allowed burst sizes. It returns the suitable burst dimension bitmap for the gadget.
At numerous factors when the memory object is accessed (including the time of elimination of the DMA resources), the driving force would possibly need to synchronize the reminiscence object with respect to varied caches. This part gives guidelines on when and how to synchronize reminiscence objects. Instance 8–3 reveals tips on how to allocate IOPB reminiscence and the mandatory DMA sources to entry it. DMA assets should still be allocated, and the DDI_DMA_CONSISTENT flag should be passed to the allocation perform.
Instance Design Architecture
Usually, the motive force has to name ddi_dma_sync(9F) when a DMA switch completes. The exception to that is that deallocating the DMA resourceswith ddi_dma_unbind_handle(9F), does an implicit ddi_dma_sync(9F) on behalf of the driving force. The resource-allocation routines present the driving force with several options when handling allocation failures. The waitfp argument indicates whether or not the allocation routines will block, return immediately, or schedule a callback, as shown Proof of personhood in Table 8–1. In Instance 8–1, xxstart() is used because the callback operate and the per-device state structure is given as its argument.
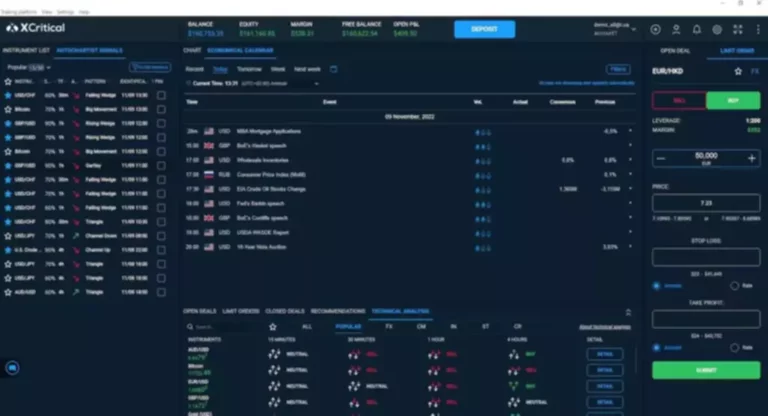
Scatter Gather With Interrupts
We’ll start with using SPI to drive ‘NeoPixel’ LEDs, then we’ll use I2C to drive a small monochorme OLED and SPI to drive a bigger colour TFT display.

This is usually carried out in the read(9E) or write(9E) routines of a character system driver. This area describes the granularity of the gadget’s DMA switch capability, in models of bytes. This worth is used to specify, for instance, the sector measurement of a mass storage device.